The purpose of this post is to provide some intuition for Bloch’s theorem, a result which might be more descriptively called the “periodic potential lemma” or even the “fundamental theorem of condensed matter physics“.
Problem #\(1\): Solve the \(1\)st order linear ODE:
\[\dot v(t)+\Gamma(t)v(t)=0\]
first for arbitrary parametric driving \(\Gamma(t)\), and then for the specific periodic driving \(\Gamma(t)=\Gamma_0\cos^2(\omega t)\).
Solution #\(1\): (solve by an integrating factor or separation of variables):



This calculation thus illustrates an example of Floquet’s theorem; the response of a first-order linear system to periodic parametric driving looks like the “free” evolution of the system with respect to the average driving (i.e. exponential growth/decay) modulated by a periodic envelope with the same period as the driving.
Problem #\(2\): What are the \(2\) key differences between having a free particle \(V=0\) and having a particle in a \(\Lambda\)-periodic potential \(V(\textbf x-\Delta\textbf x)=V(\textbf x),\Delta\textbf x\in\Lambda\)
Solution #\(2\):

The \(\Lambda\)-periodic function \(u_{\textbf k}(\textbf x)\) is in general something complicated and so in practice not that useful. However, one can equivalently formulate Bloch’s theorem without mentioning it all:
Problem #\(3\): Let \(\Lambda\) be a Bravais lattice, let \(H_{\Lambda}\) be a Hamiltonian with \(\Lambda\)-periodic potential, and let \(\psi(\textbf x)\) be an \(H_{\Lambda}\)-eigenstate. Then the following \(2\) propositions are logically equivalent:
- There exists a crystal quasimomentum \(\textbf k\in\textbf R^3/\Lambda^*\) and a \(\Lambda\)-periodic function \(u_{\textbf k}(\textbf x)\) such that \(\psi(\textbf x)=u_{\textbf k}(\textbf x)e^{i\textbf k\cdot\textbf x}\).
- There exists a crystal quasimomentum \(\textbf k\in\textbf R^3/\Lambda^*\) such that for all \(\Delta\textbf x\in\Lambda\):
\[\psi(\textbf x-\Delta\textbf x)=e^{-i\textbf k\cdot\Delta\textbf x}\psi(\textbf x)\]
Solution #\(3\): Trivial, but still good to fully think it through. In practical problem-solving, the way one actually uses Bloch’s theorem is frequently via formulation #\(2\).
Proof: The Bravais lattice \(\Lambda\) is a subgroup of the translation group \(\textbf R^3\), so we can invoke the usual unitary representation \(\Delta\textbf x\mapsto e^{-i\Delta\textbf x\cdot\textbf P/\hbar}\) where \(\textbf P\) is the generator of the Lie group of translations \(\textbf R^3\). Due to the induced \(\Lambda\)-periodicity of the crystal Hamiltonian \(H\), it follows that \(e^{i\Delta\textbf x\cdot\textbf P/\hbar}He^{-i\Delta\textbf x\cdot\textbf P/\hbar}=H\), or equivalently \([H,e^{-i\Delta\textbf x\cdot\textbf P/\hbar}]=0\). However, because \(\Lambda\) itself is not a Lie group, its associated discrete translational symmetry by only the lattice vectors \(\Delta\textbf x\in\Lambda\) is non-Noetherian and therefore it would be false to claim that the momentum \(\textbf P\) of states is conserved \([H,\textbf P]\neq 0\). Nevertheless, the fact that the crystal Hamiltonian \([H,e^{-i\Delta\textbf x\cdot\textbf P/\hbar}]=0\) commutes with the entire \(\Lambda\)-representation is all we need to prove Bloch’s theorem. Because \(\Lambda\) has the structure of an additive, hence abelian group, its complex irreducible subrepresentations act on one-dimensional eigenspaces by Schur’s lemma (obvious if you think transitively!) each of which is spanned by some plane wave \(|\textbf k\rangle\) and therefore indexed by crystal momentum \(\textbf k\in\textbf R^3\). By Schur’s lemma again, each of these plane waves are also \(H\)-eigenstates \(|\textbf k\rangle=|E_{\textbf k}\rangle\). In other words, the state \(|-\textbf k\rangle\otimes |E_{\textbf k}\rangle\in\mathcal H^{\otimes 2}\) obeys \(e^{-i\Delta\textbf x\cdot\textbf P_{\mathcal H^{\otimes 2}}/\hbar}\left(|-\textbf k\rangle\otimes|E_{\textbf k}\rangle\right)=e^{-i\Delta\textbf x\cdot\textbf P_{\mathcal H}/\hbar}|-\textbf k\rangle\otimes e^{-i\Delta\textbf x\cdot\textbf P_{\mathcal H}/\hbar}|E_{\textbf k}\rangle=e^{i\textbf k\cdot\Delta\textbf x}e^{-i\textbf k\cdot\Delta\textbf x}|-\textbf k\rangle\otimes|E_{\textbf k}\rangle=|-\textbf k\rangle\otimes|E_{\textbf k}\rangle\). But eigenfunctions of translation with eigenvalue \(1\) are synonymous with periodic functions. This is the periodic amplitude modulation \(u_{\textbf k}(\textbf x)=\langle\textbf x|\otimes\langle\textbf x|-\textbf k\rangle\otimes|E_{\textbf k}\rangle\).
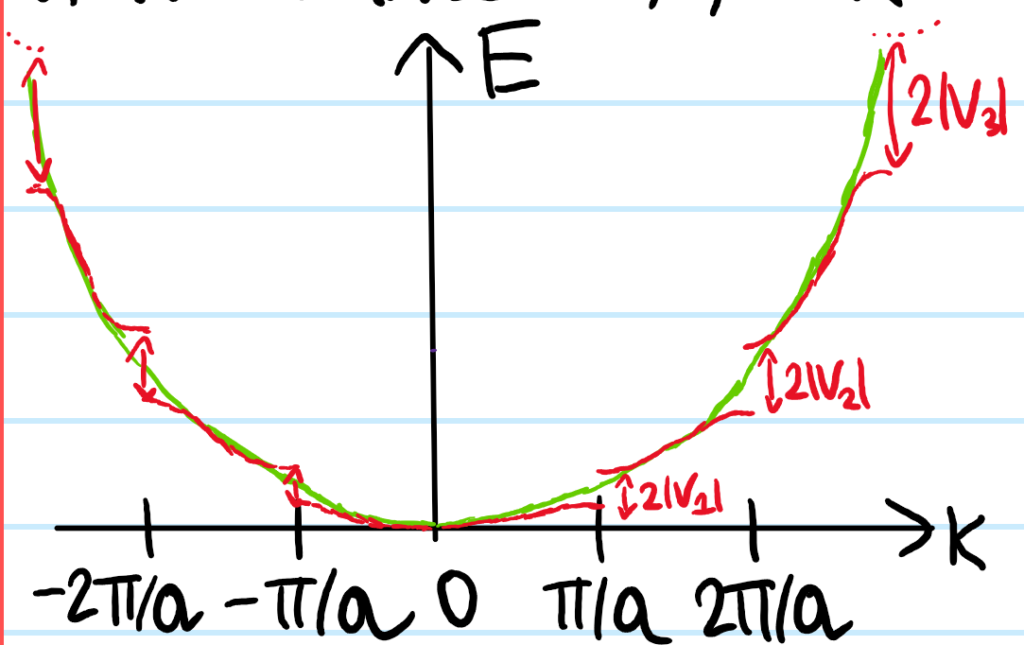
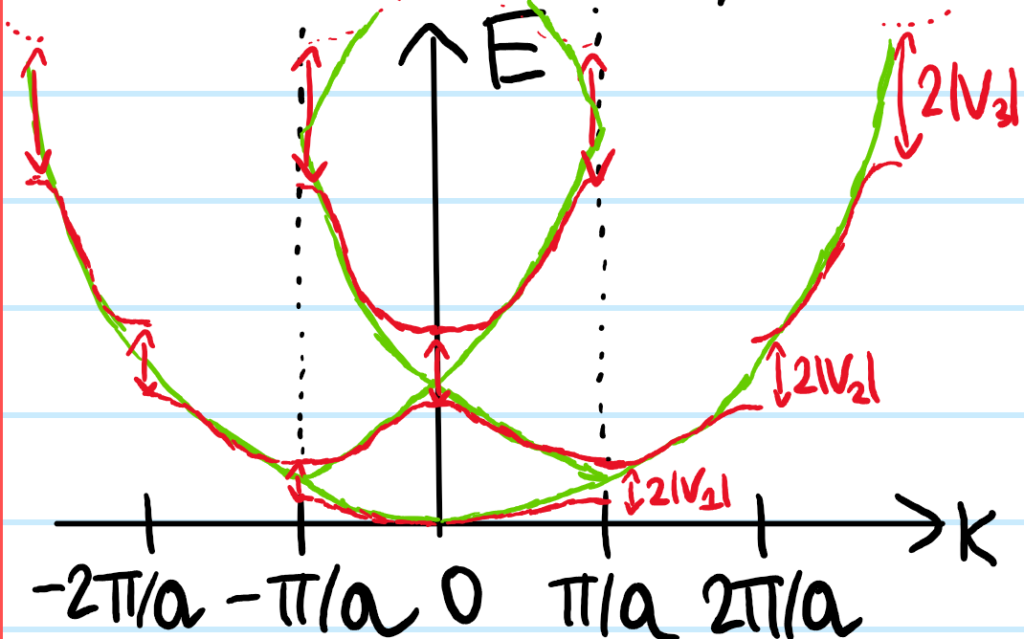
Above in the proof of Bloch’s theorem, it was emphasized that the momentum \(\textbf P\) of states is not conserved. However, it turns out that the crystal momentum \(\hbar\textbf k\) is conserved modulo the reciprocal lattice \(\Lambda^*\). This follows from the form of the Bloch \(H\)-eigenstates in the crystal and the fact that one of the ways to define a reciprocal lattice vector \(\Delta\textbf k\in\Lambda^*\) is by the requirement that \(e^{i\Delta\textbf k\cdot\textbf x}=1\) for all real space lattice vectors \(\textbf x\in\Lambda\). The above discussion with the crystal momentum \(\textbf k\in\textbf R^3\) therefore took place in the extended (Brillouin) zone scheme, whereas the restriction of the crystal momentum \(\textbf k\in\Gamma_{\Lambda^*}\) to the first Brillouin zone is called the reduced (Brillouin) zone scheme. In the reduced scheme however, the Bloch \(H\)-eigenstates can no longer just be labelled like \(|E_{\textbf k}\rangle\), one needs an additional energy band index \(n\in\textbf Z^+\) to describe which energy band one is in; thus \(|E\rangle=|E_{\textbf k,n}\rangle\).
Born-Von Karmen Boundary Conditions
Although the Bloch form of the \(H\)-eigenstates \(\langle\textbf x|E_{\textbf k}\rangle=\langle x|\textbf k\rangle u_{\textbf k}(\textbf x)\) contain a \(\Lambda\)-periodic part \(u_{\textbf k}(\textbf x)\), the \(H\)-eigenstate \(|E_{\textbf k}\rangle\) itself does not immediately have any kind of periodicity associated to it unless its crystal momentum \(\textbf k\in\textbf R^3\) happens to land exactly on a reciprocal lattice point \(\textbf k\in\Lambda^*\) in which case the plane wave \(e^{i\textbf k\cdot\textbf k}\) would also be \(\Lambda\)-periodic and thereby absorbed into \(u_{\textbf k}(\textbf x)\) factor, ensuring that \(\langle\textbf x|E_{\textbf k}\rangle\) would be \(\Lambda\)-periodic. But \(\Lambda^*\) is a set of measure zero in \(\textbf R^3\), so this isn’t a reliable source of periodicity. Instead, we can simply enforce periodic boundary conditions (also called Born-von Karmen boundary conditions) on the \(H\)-eigenstate. Specifically, if the crystal is a rectangular prism with \(N_j\) atoms along the \(j\)-th primitive lattice vector \(\textbf a_j\) direction, then we enforce it to be \(N_j\)-periodic along \(\textbf a_j\), i.e. \(\langle \textbf x+N_j\textbf a_j|E_{\textbf k}\rangle\) for each \(j=1,2,3\) (not to be confused as an Einstein series!). This is clearly compatible with Bloch’s theorem provided the crystal momentum \(\textbf k\) satisfies \(e^{iN_j\textbf k\cdot\textbf a_j}=1\) for each \(j\in\{1,2,3\}\). Note that this doesn’t necessarily imply that \(\textbf k\in\Lambda^*\) since it only holds at some \(N_j\textbf a_j\in\Lambda\) not at every Bravais lattice point in \(\Lambda\). More precisely, we can still express the crystal momentum \(\textbf k\) in the reciprocal basis \(\textbf a^1,\textbf a^2,\textbf a^3\) just that the coefficients of such a linear combination need not be integers and hence \(\textbf k\) need not be in \(\Lambda^*\). More precisely, one can check using \(\textbf a^j\textbf a_k=2\pi\delta^j_k\) that the Born-von Karmen boundary conditions are logically equivalent to \(\textbf k=\sum_{j=1}^3\frac{n_j}{N_j}\textbf a^j\) for any choice of three integers \(n_j\in\textbf Z\). Thus, the Born-von Karmen boundary conditions quantize the wavevector \(\textbf k=\textbf k_{n_1,n_2,n_3}\) to lie in a lattice \(\text{span}_{\textbf Z}(\textbf a^1/N_1,\textbf a^2/N_2,\textbf a^3/N_3)\) which contains the reciprocal lattice \(\Lambda^*\subseteq\text{span}_{\textbf Z}(\textbf a^1/N_1,\textbf a^2/N_2,\textbf a^3/N_3)\) as a sublattice.
Armed with this discretization of reciprocal space given by the Born-von Karmen boundary conditions, it makes sense to ask how many \(H\)-eigenstates are associated by Bloch’s theorem to a crystal momentum \(\textbf k\in\Gamma_{\Lambda^*}\) which lies within the first Brillouin zone? In other words, what is the cardinality of the intersection \(\Gamma_{\Lambda^*}\cap\text{span}_{\textbf Z}(\textbf a^1/N_1,\textbf a^2/N_2,\textbf a^3/N_3)\)? The answer is independent of what the particular Bravais lattice \(\Lambda\) is (and hence what \(\Lambda^*\) is) because regardless of its exact nature, in all cases the volume \(V^*\) of the Brillouin zone in reciprocal space is \(V^*=|\textbf a^1\cdot(\textbf a^2\times\textbf a^3)|\) (this is because the Brillouin zone is just the Wigner-Seitz cell of \(\Lambda^*\) which itself is just a particularly symmetric choice of primitive unit cell and all primitive unit cells of any Bravais lattice have the same volume). Therefore, within this volume \(V^*\) one can fit approximately \(N_1N_2N_3\) little parallelepipeds with sides \(\textbf a^1/N_1,\textbf a^2/N_2,\textbf a^3/N_3)\). But each parallelepiped corresponds to a Bloch \(H\)-eigenstate, so this argument proves that \(\#\Gamma_{\Lambda^*}\cap\text{span}_{\textbf Z}(\textbf a^1/N_1,\textbf a^2/N_2,\textbf a^3/N_3)=N:=N_1N_2N_3\) is the total number of atoms in the entire crystal (again, when subject to Born-von Karmen boundary conditions).
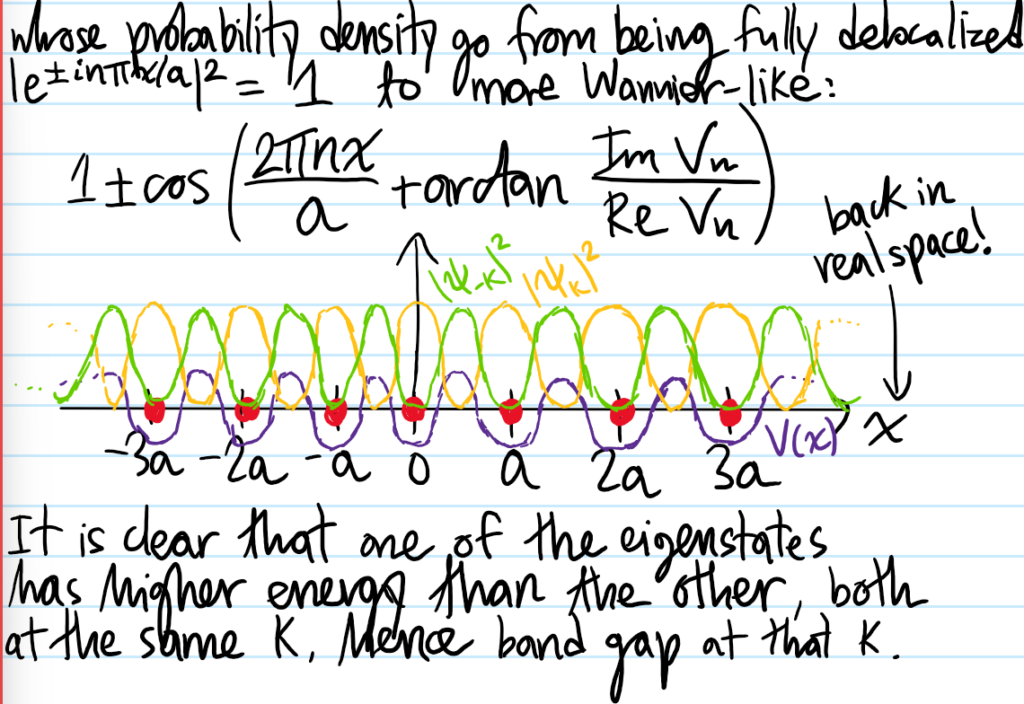
Wannier Wavefunctions
Another important property of the Bloch \(H\)-eigenstates is that they are very much delocalized in \(\textbf x\)-space since the probability density \(|\langle\textbf x|E_{\textbf k}\rangle|^2=|u_{\textbf k}(\textbf x)|^2\) is at least \(\Lambda\)-periodic, hence delocalized. In line with the Heisenberg uncertainty principle, these Bloch \(H\)-eigenstates are also very much localized in \(\textbf k\)-space. It therefore makes sense that, if we instead view the Bloch \(H\)-eigenstate \(\langle\textbf x|E_{\textbf k}\rangle\) not so much as a function of \(\textbf x\) but as a function of the crystal momentum \(\textbf k\), then we can imagine running a unitary Fourier transform from \(\textbf k\mapsto\textbf x\) which by Heisenberg again should produce a more localized wavefunction in \(\textbf x\)-space. Indeed, these wavefunctions are called Wannier wavefunctions \(w(\textbf x-\textbf x_0)\) defined as described above (the normalization factor \(N\) comes from the argument in the preceding section using the Born-Von Karmen boundary conditions):
\[w(\textbf x-\textbf x_0):=\frac{1}{\sqrt N}\sum_{\textbf k\in\Gamma_{\Lambda^*}}e^{-i\textbf k\cdot\textbf x_0}\langle\textbf x|E_{\textbf k}\rangle\]
where the way the argument is written emphasizes the Wannier wavefunctions are associated each atomic site \(\textbf x_0\in\Lambda\) in the Bravais lattice (check this using Bloch’s theorem). The Wannier wavefunctions are no longer wavefunctions of \(H\)-eigenstates since they can’t be written in Bloch form. They also suffer a gauge redundancy, which opens up the whole topic of maximally localized Wannier functions (MLWF); see this paper of Marzari, Vanderbilt, et al. By the unitarity of the Fourier transform as encoded by Plancherel’s theorem, the Wannier wavefunctions are orthonormal with respect to distinct atomic sites \(\iiint_{\textbf x\in\textbf R^3}w^*(\textbf x-\textbf x_1)w(\textbf x-\textbf x_2)d^3\textbf x=\delta_{\textbf x_1,\textbf x_2}\). The inverse unitary Fourier transform gives the delocalized Bloch \(H\)-eigenstate as a superposition of the localized Wannier wavefunctions:
\[\langle\textbf x|E_{\textbf k}\rangle=\frac{1}{\sqrt N}\sum_{\textbf x_0\in\Lambda}e^{i\textbf k\cdot\textbf x_0}w(\textbf x-\textbf x_0)\]
As a general rule of thumb, it seems that Bloch wavefunctions are a more suitable basis for conductors, etc. where the electrons \(e^-\) are known to be nearly free and delocalized in energy bands whereas Wannier wavefunctions are a more suitable basis for insulators and materials described by tight-binding Hamiltonians where the electrons \(e^-\) are known to be more localized.