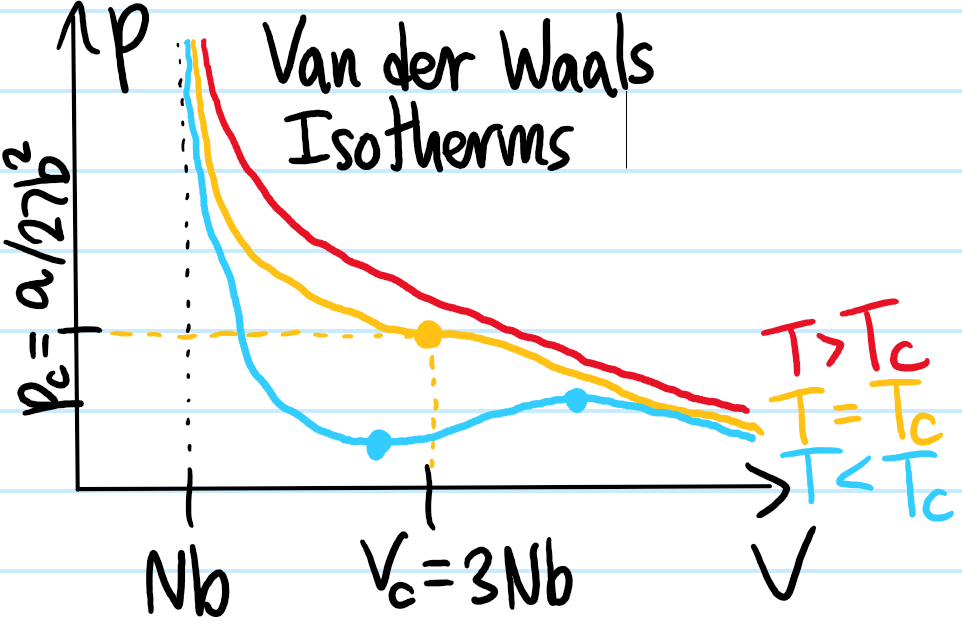
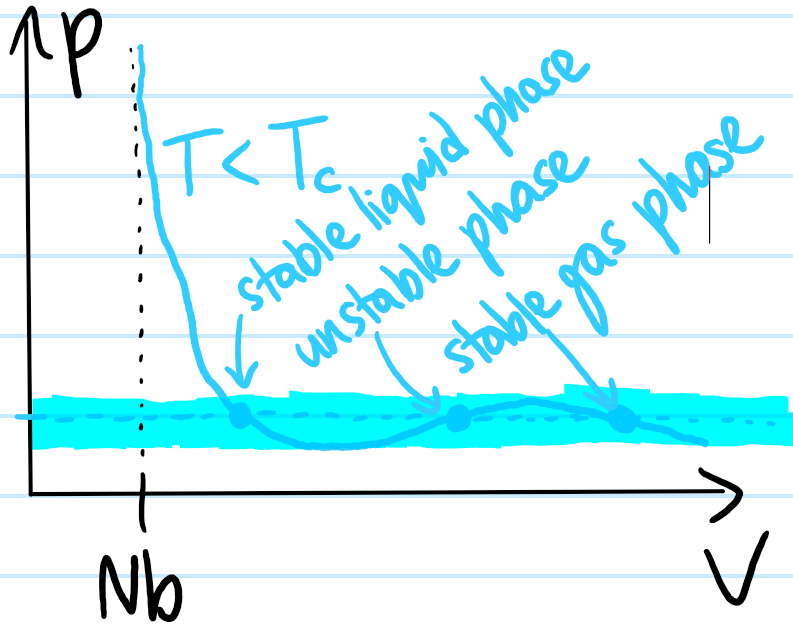
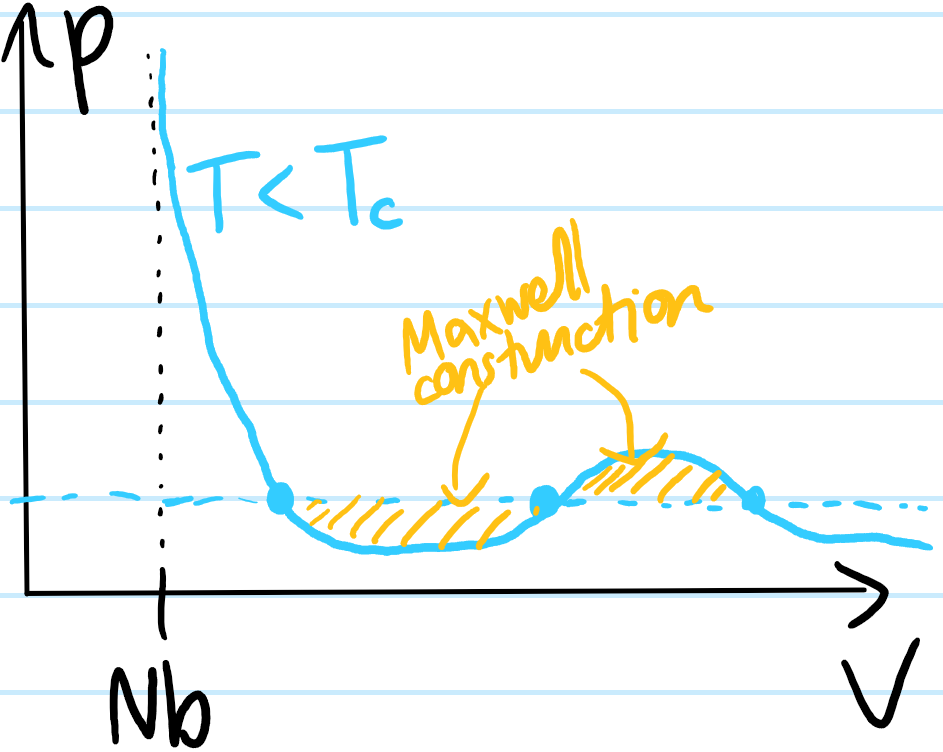
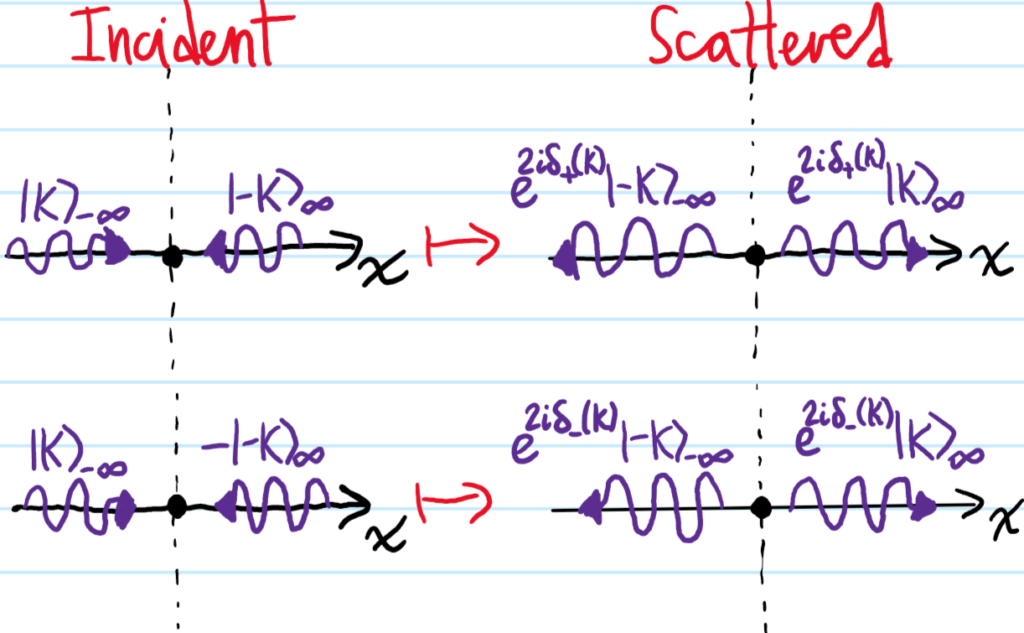
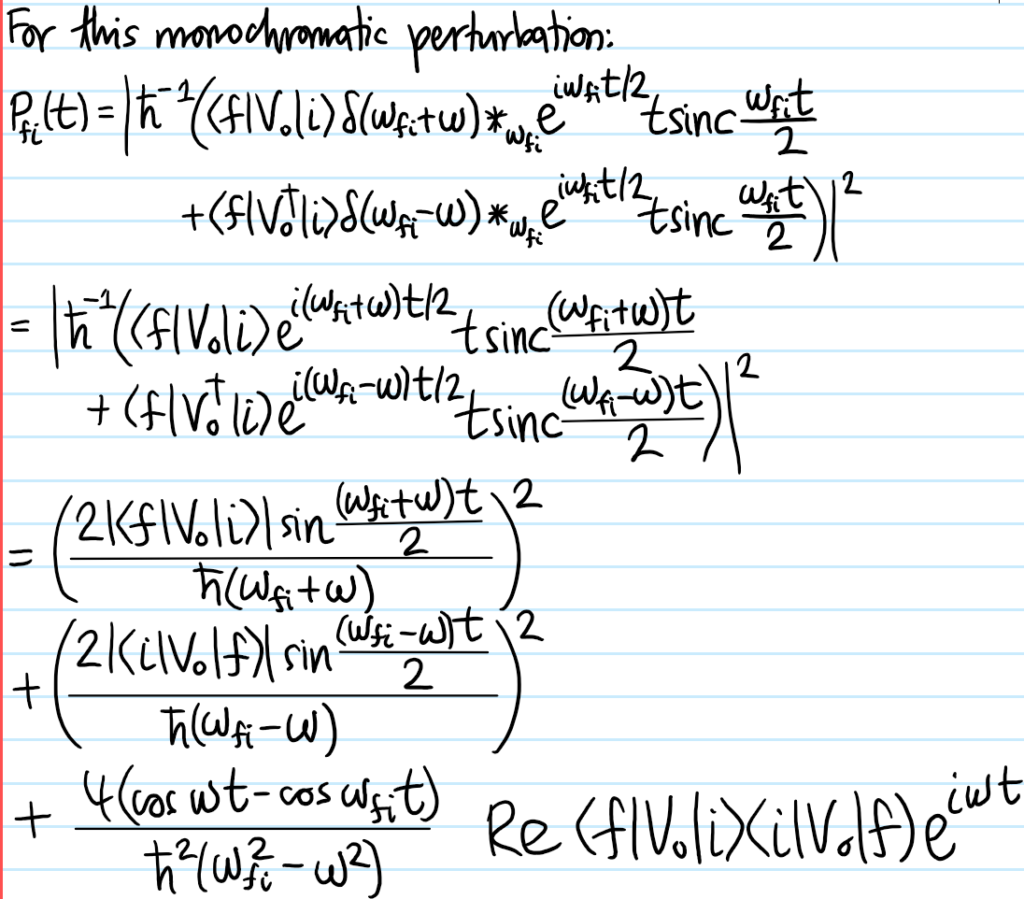Problem: Write down the Lagrangian \(L\) of a nonrelativistic classical point charge \(q\) of mass \(m\) moving in an electromagnetic field. Justify it.
Solution: \(L=T-V\) as usual where the nonrelativistic kinetic energy \(T=m|\dot{\mathbf x}|^2/2\) (if it were relativistic then \(T=-mc^2/\gamma_{|\dot{\mathbf x}|}\)) and the velocity-dependent electromagnetic potential energy \(V\) must be written in terms of the electromagnetic gauge potentials:
\[V=q(\phi(\mathbf x,t)-\dot{\mathbf x}\cdot\mathbf A(\mathbf x,t))\]
The ultimate justification for this choice of \(L\) is that the corresponding Euler-Lagrange equations reproduce the nonrelativistic Lorentz force law:
\[m\ddot{\mathbf x}=q(\mathbf E(\mathbf x,t)+\dot{\mathbf x}\times\mathbf B(\mathbf x,t))\]
where \(\textbf E=-\frac{\partial\phi}{\partial\textbf x}-\frac{\partial\textbf A}{\partial t}\) and \(\textbf B=\frac{\partial}{\partial\textbf x}\times\textbf A\).
However, it can be motivated by the fact that the interaction portion of the action \(S_V=-q\int d\tau v^{\mu}A_{\mu}=-\int dt V\) is manifestly a Lorentz scalar so in particular by time dilation \(dt/d\tau=\gamma\) one recovers the above form of \(V\).
Problem: Compute the corresponding Hamiltonian \(H\) of the nonrelativistic charge \(q\) of mass \(m\) in the electromagnetic field. Hence, derive the minimal coupling rule.
Solution: One has the conjugate momentum \(\mathbf p=\frac{\partial L}{\partial\mathbf x}=m\dot{\mathbf x}+q\mathbf A(\mathbf x,t)\) which in particular is not the usual \(m\dot{\mathbf x}\) momentum due to the additional magnetic contribution \(q\mathbf A\) from the velocity-dependent magnetic potential. The Hamiltonian can thus be computed to obey the minimal coupling rule \(\mathbf p\mapsto\mathbf p-q\mathbf A\):
\[H:=\dot{\textbf x}\cdot\textbf p-L=\frac{|\textbf p-q\textbf A(\textbf x,t)|^2}{2m}+q\phi(\textbf x,t)\]
Problem: Comment on how the Lagrangian \(L\) and Hamiltonian \(H\) behave under electromagnetic gauge transformations \(A^{\mu}\mapsto A^{\mu}+\partial^{\mu}\Gamma\).
Solution: \(L\) is not gauge invariant, rather accumulating a total time derivative \(L\mapsto L-q\dot{\Gamma}\). On the other hand, \(H\) changes by a partial time derivative \(H\mapsto H+q\frac{\partial\Gamma}{\partial t}\). The equations of motion (whether in the form of Euler-Lagrange or Hamilton) are of course gauge invariant since \(\mathbf E,\mathbf B\) are gauge invariant.
Problem: A simple case of the above formalism consists of a non-relativistic point charge \(q\) of mass \(m\) in a uniform magnetic field, thus \(\mathbf E=\mathbf 0\) (hence \(\phi=0\)) and \(\mathbf B=B\hat{\mathbf z}\). What are some suitable choices of the gauge field \(\mathbf A\)?
Solution: Physically, one is looking for a “flow field” \(\mathbf A(\mathbf x)\) whose vorticity will generate a \(\textbf B=\frac{\partial}{\partial\textbf x}\times\textbf A\) that points uniformly along \(z\). The \(2\) obvious ways to set this up are either in a “river” manner like \(\mathbf A=-By\hat{\mathbf x}\) or \(\mathbf A=Bx\hat{\mathbf y}\) (both examples of the Landau gauge) or in a “whirlpool” manner like \(\mathbf A=\mathbf B\times\mathbf x/2\) (called the symmetric gauge, cf. familiar fluid mechanics result \(\frac{\partial}{\partial\mathbf x}\times(\boldsymbol{\omega}\times\mathbf x)=2\boldsymbol{\omega}\)).
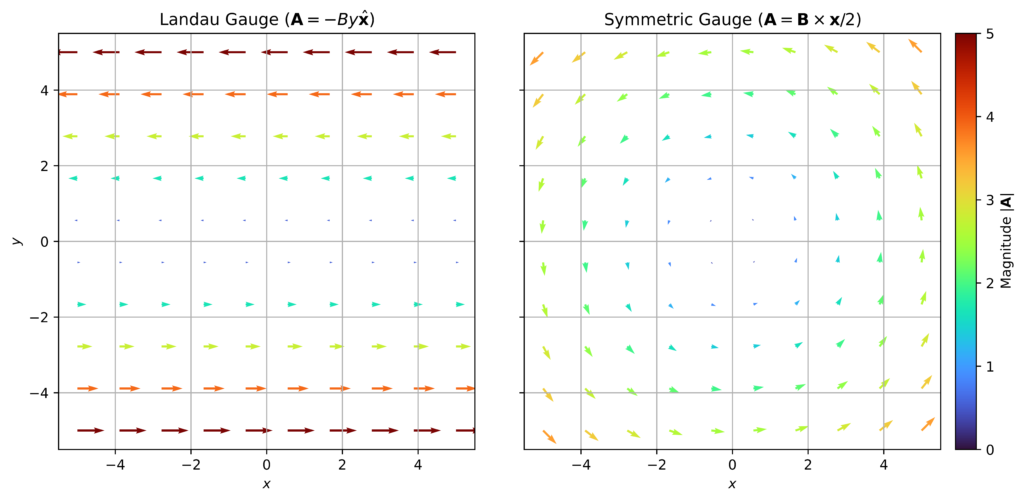
Problem: Now assume the point charge is a quantum particle and begin by working in the Landau gauge \(\mathbf A_L=-By\hat{\mathbf x}\). Diagonalize the corresponding Hamiltonian \(H=|\mathbf P-q\mathbf A_L|^2/2m\).
Solution: Expanding and completing the square:
\[H=\frac{P_y^2}{2m}+\frac{m\omega_B^2}{2}\left(Y+\frac{p_x}{m\omega_B}\right)^2+\frac{p_z^2}{2m}\]
where \(p_x,p_z\in\mathbf R\) are the momentum eigenvalues in the \(x\) and \(z\) directions since \([H,P_x]=[H,P_z]=0\) and \(\omega_B=qB/m\) is the classical cyclotron frequency. Meanwhile, in the \(y\)-direction, the Hamiltonian is identical to that of a (displaced) \(1\)D quantum harmonic oscillator with natural frequency \(\omega_B\); this defines the corresponding characteristic length scale \(\ell_B=\sqrt{\hbar/m|\omega_B|}=\sqrt{\hbar/|q|B}\) (called the magnetic length) and characteristic momentum scale \(p_B=\sqrt{\hbar m|\omega_B|}=\sqrt{\hbar |q|B}\) of the oscillator. The energies (called Landau levels) are:
\[E_{n,p_z}=\hbar\omega_B(n+1/2)+\frac{p_z^2}{2m}\]
and (not gauge-invariant) position-space wavefunctions:
\[\psi_{n,p_x,p_z}(x,y,z)\sim e^{i(p_xx+p_zz)/\hbar}H_n\left(\frac{y+p_x/m\omega_B}{\ell_B}\right)e^{-(y+p_x/m\omega_B)^2/2\ell_B^2}\]
Problem: Show that the \(n^{\text{th}}\) Landau level has degeneracy \(\dim\ker(H-E_{n,p_z=0}1)=\Phi_{\mathbf B}/\Phi_{\mathbf B,0}\) with \(\Phi_{\mathbf B}\) the magnetic flux through the plane perpendicular to \(\mathbf B\) and \(\Phi_{\mathbf B,0}=h/|q|\) the quantum of magnetic flux.
Solution: The degeneracy arises from the fact that \(E_{n,p_z=0}\) doesn’t depend on the \(p_x\) eigenvalue even though \(\psi_{n,p_x,p_z=0}\) does. If the system were infinitely large, then \(p_x\in\mathbf R\) would cause each Landau level to be uncountably degenerate; therefore, assume the system lives in a rectangle of dimensions \(L_x\times L_y\) (as \(p_z=0\) the system is effectively confined to the \(xy\)-plane). Then \(p_x\in\hbar\frac{2\pi}{L_x}\mathbf Z\) is quantized, which leads to quantization of the oscillator’s equilibrium \(y_0=-p_x/m\omega_B\in\frac{h}{m\omega_BL_x}\mathbf Z\) with adjacent equilibria separated by \(\Delta y_0=\frac{h}{m|\omega_B|L_x}\). Since this must lie in an interval of width \(L_y\), one obtains the degeneracy:
\[\dim\ker(H-E_{n,p_z=0}1)=\frac{L_y}{\Delta y_0}=\frac{\Phi_{\mathbf B}}{\Phi_{\mathbf B,0}}\]
since \(\Phi_{\mathbf B}=BL_xL_y\); note the result is independent of mass \(m\), independent of the sign of the charge \(q\), and also independent of \(n\in\mathbf N\), indicating all Landau levels are equally degenerate. Furthermore, if one plugs some numbers in (e.g. \(B=1\text{ T}\) for an electron or proton), one finds that each Landau level has a mind-boggling degeneracy per unit area \(B/\Phi_{\mathbf B,0}\sim 10^{14}\frac{\text{states}}{\text{Landau level}\times{\text m^2}}\).
Problem: Derive the structure of Landau levels again but this time using the symmetric gauge \(\mathbf A_S=\mathbf B\times\mathbf x/2\).
Solution: A property of the earlier Landau gauge \(\mathbf A_L\) that was not mentioned (because it wasn’t necessary) is that it is also a Coulomb gauge \(\frac{\partial}{\partial\mathbf x}\cdot\mathbf A_L=0\). In general, whenever \(\frac{\partial}{\partial\mathbf x}\cdot\mathbf A=0\) for some gauge field \(\mathbf A\), there is a useful simplification that can be made on the cross-terms:
\[|\mathbf P-q\mathbf A|^2=|\mathbf P|^2+q^2|\mathbf A|^2-q(\mathbf P\cdot\mathbf A+\mathbf A\cdot\mathbf P)=|\mathbf P|^2+q^2|\mathbf A|^2-2q\mathbf A\cdot\mathbf P\]
namely the dot-product commutator \(\mathbf P\cdot\mathbf A-\mathbf A\cdot\mathbf P=-i\hbar\left(\frac{\partial}{\partial\mathbf X}\cdot\mathbf A\right)\) vanishes iff one works in a Coulomb gauge. It so happens that the symmetric gauge \(\mathbf A_S\) is also a Coulomb gauge \(\frac{\partial}{\partial\mathbf x}\cdot\mathbf A_S=0\), so this time exploit this lemma:
\[H=\frac{|\mathbf P-q\mathbf A_S|^2}{2m}=\frac{|\mathbf P|^2}{2m}+\frac{1}{2}m\left(\frac{\omega_B}{2}\right)^2\rho^2-\frac{\omega_B}{2}L_z\]
Since \([H,P_z]=[H,L_z]=0\) (the latter is the whole point of using the symmetric gauge!), one can analyze this \(2\)D isotropic harmonic oscillator in polar coordinates \(\psi(\rho,\phi,z)=R(\rho)e^{im_{\ell}\phi}e^{ip_zz/\hbar}\) such that the radial Schrodinger equation is:
\[\left[ -\frac{\hbar^2}{2m} \left( \frac{d^2}{d \rho^2} + \frac{1}{\rho}\frac{d}{d \rho} – \frac{m_\ell^2}{\rho^2} \right) + \frac{1}{8} m \omega_B^2 \rho^2 – \frac{\hbar \omega_B}{2} m_\ell + \frac{p_z^2}{2m}\right] R=ER\]
which has solutions parameterized by a radial quantum number \(n_{\rho}\in\mathbf N\) and \(m_{\ell}\in\mathbf Z\):
\[R_{n_{\rho},m_{\ell}}(\rho)\sim\rho^{|m_\ell|} e^{-\rho^2 / 4\ell_B^2} L_{n_{\rho}}^{|m_\ell|}\left( \frac{\rho^2}{2\ell_B^2} \right)\]
and energies:
\[E_{n_{\rho},m_{\ell},p_z}=\hbar\omega_B\left(n_{\rho}+\frac{|m_{\ell}|-m_{\ell}}{2}+1/2\right)+\frac{p_z^2}{2m}\]
or from ML, \(|m_{\ell}|-m_{\ell}=2\text{ReLU}(-m_{\ell})\) so defining \(n:=n_{\rho}+\text{ReLU}(-m_{\ell})\) ensures this coincides with the Landau level energies obtained earlier in a Landau gauge (how to show that the Landau levels still have the same degeneracy?).
Problem: How do the above results compare with the classical solution that the charge spirals along \(\mathbf B\) at the cyclotron frequency \(\omega_B\)?
Solution: Using the Landau gauge \(\mathbf A_L=-By\hat{\mathbf x}\) amounts to perfectly knowing the \(x\)-component \(p_x\) of the charge’s conjugate momentum at the expense of completely smearing it out (\(e^{ip_xx/\hbar}\)) in that direction. By contrast, with the symmetric gauge \(\mathbf A_S=\mathbf B\times\mathbf x/2\), the wavefunctions are isotropic, more closely matching the classical intuition…but none of these wavefunctions are gauge invariant (indeed, the exact \(U(1)\) gauge transformation they undergo is described below) so don’t read into them too much.
Quantum Gauge Theory
Suppose we insist that the Schrodinger equation be gauge covariant under the gauge transformations of the potentials \(\phi\mapsto\phi’=\phi+\frac{\partial\Gamma}{\partial t}\) and \(\textbf A\mapsto\textbf A’=\textbf A-\frac{\partial\Gamma}{\partial\textbf x}\). The novelty is that the state \(|\psi\rangle\mapsto |\psi’\rangle=U_{\Gamma}|\psi\rangle\) will have to transform too under the gauge transformations (which we postulate occurs via some linear operator \(U_{\Gamma}\)) in order to have any hope of maintaining gauge covariance. Thus, the Hamiltonian becomes \(H\mapsto H’=H+q\frac{\partial\Gamma}{\partial t}\) and we demand by gauge covariance that \(i\hbar\dot{|\psi’\rangle}=H’|\psi’\rangle\) in addition to \(i\hbar\dot{|\psi\rangle}=H|\psi\rangle\). With these two equations in mind, one can show that \(U_{\Gamma}\) satisfies the differential equation:
\[i\hbar\frac{\partial U_{\Gamma}}{\partial t}=[H,U_{\Gamma}]+q\frac{\partial\Gamma}{\partial t}U_{\Gamma}\]
If we assume for a moment that \([H,U_{\Gamma}]=0\) commute, then the resultant ODE is easy to integrate and gives:
\[U_{\Gamma}(\textbf X,t)=e^{-iq\Gamma(\textbf X,t)/\hbar}\]
which is indeed a local unitary phase as it was suggestively written all along. This suggests a new interpretation of the gauge \(\Gamma\), namely it is a generator of translations in charge space \(q\in\textbf R\), adding more or less charge to the system. The assumption earlier that \([H,U_{\Gamma}]=0\) amounts to conservation of electric charge?
There is another way to see why the above is the correct gauge transformation of states, even if its derivation was a little handwavy. Specifically, if one defines the four-covector operator \(\mathcal D:=\frac{\partial}{\partial X}+\frac{iq}{\hbar}A\) with corresponding covariant components \(\mathcal D_{\mu}=\partial_{\mu}+\frac{iqA_{\mu}}{\hbar}\) for spacetime index \(\mu=0,1,2,3\), then the Schrodinger equation looks like that for a free particle (descending from kets to wavefunctions \(|\psi\rangle\mapsto\psi(\textbf x,t)\)):
\[i\hbar c\mathcal D_0\psi=-\frac{\hbar^2}{2m}\mathcal D^2\psi\]
where \(\mathcal D^2:=\mathcal D_1^2+\mathcal D_2^2+\mathcal D_3^2\). Now then, check (using the product rule and \([A_{\mu},U_{\Gamma}]=0\)) that each \(\mathcal D_{\mu}\psi\mapsto U_{\Gamma}\mathcal D_{\mu}\psi\) under the gauge transformation \(\Gamma\) so the Schrodinger equation is thus gauge invariant since \(D_{\mu}U_{\Gamma}=U_{\Gamma}D_{\mu}\) as operators (though the Schrodinger equation is not Lorentz covariant! That’s a topic for another time).