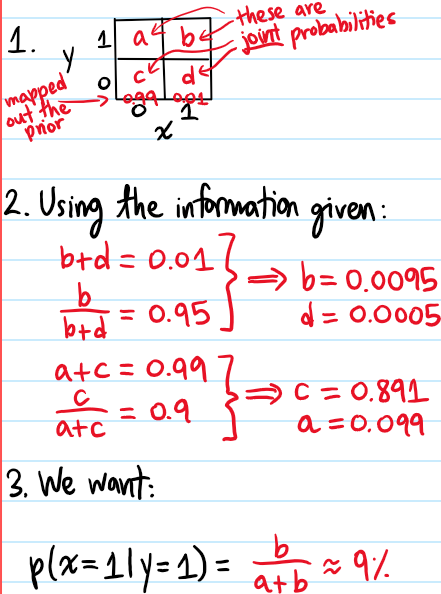
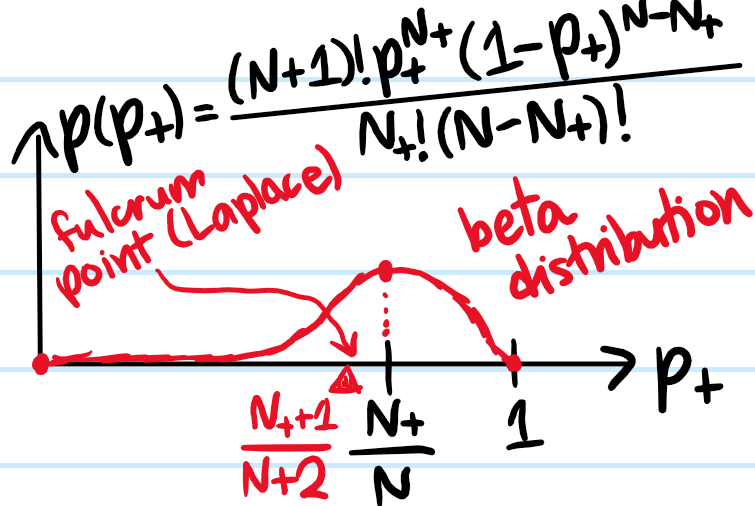
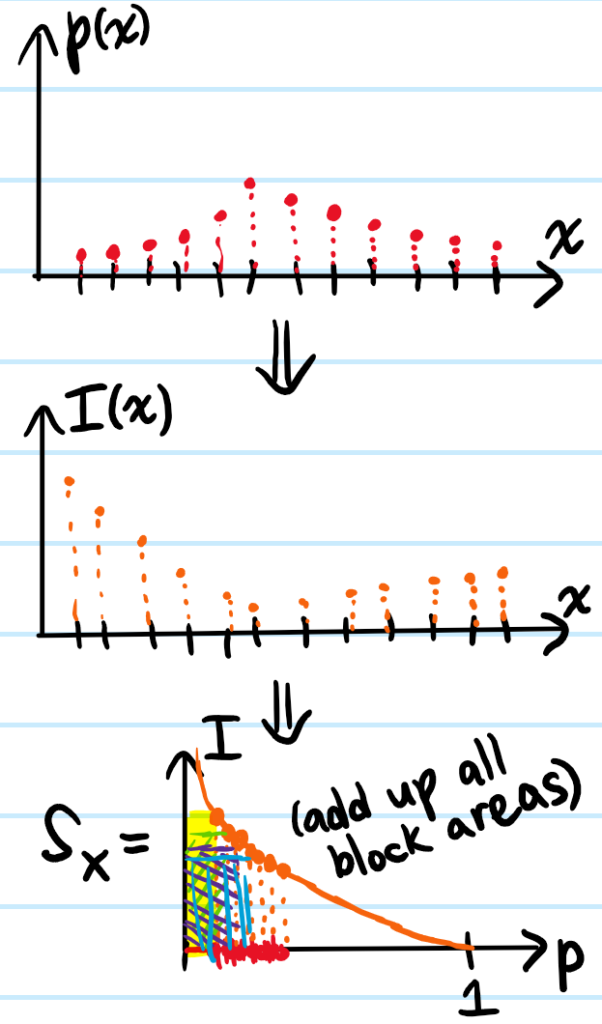
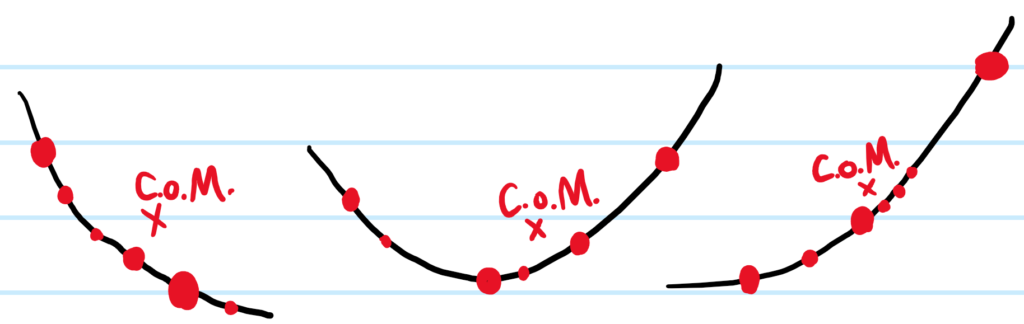
Problem: Illustrate some of the basic fundamentals involved in using the PyTorch deep learning library. In particular, discuss the attributes of PyTorch tensors (e.g. dtype, CPU/GPU devices, etc.), how to generate random PyTorch tensors with/without seeding, and operations that can be performed on and between PyTorch tensors.
Solution:
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
print(torch.__version__)
2.9.1+cu128
# scalars are the most basic type of PyTorch tensor
scalar = torch.tensor(8)
print(scalar)
print(scalar.ndim)
print(scalar.item())
tensor(8) 0 8
vector = torch.tensor([7, 7])
print(vector)
print(vector.ndim)
print(vector.shape)
tensor([7, 7]) 1 torch.Size([2])
# MATRIX
MATRIX = torch.tensor([[7, 8],
[9, 10]])
print(MATRIX)
print(MATRIX.ndim)
print(MATRIX.shape)
print(MATRIX[1])
tensor([[ 7, 8],
[ 9, 10]])
2
torch.Size([2, 2])
tensor([ 9, 10])
# TENSOR
TENSOR = torch.tensor([[[1, 2, 3], [3, 6, 9], [2, 4, 6]]])
print(TENSOR)
print(TENSOR.ndim)
print(TENSOR.shape)
print(TENSOR.shape[0])
tensor([[[1, 2, 3],
[3, 6, 9],
[2, 4, 6]]])
3
torch.Size([1, 3, 3])
1
my_tensor = torch.tensor([[[[[[[[[[[[[[[[[[[[[[[[[[2, 4, 2, 3]]]]]]]]]]]]]]]]]]]]]]]]]])
print(my_tensor.ndim) # number of onion layers of square brackets
print(my_tensor.shape) # number of elements within each onion layer
26 torch.Size([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 4])
Random Tensors¶
Why random tensors?
Random tensors are important because the way many neural networks learn is that they start with tensors full of random numbers and then adjust those random numbers to better represent the data.
Start with random numbers -> look at data -> update random numbers -> look at data -> update random numbers
# Creating a random tensor of size (3, 4)
random_tensor = torch.rand(3, 4)
random_tensor
tensor([[0.0879, 0.6826, 0.4789, 0.1849],
[0.7974, 0.9331, 0.8372, 0.3934],
[0.4137, 0.7374, 0.8922, 0.0088]])
random_image_size_tensor = torch.rand(size=(3, 224, 224))
random_image_size_tensor.shape, random_image_size_tensor.ndim
(torch.Size([3, 224, 224]), 3)
plt.imshow(random_image_size_tensor[1])
<matplotlib.image.AxesImage at 0x7f2eb56a1930>

zero_tensor = torch.zeros(size=(3, 4))
one_tensor = torch.ones(size=(3, 4))
print(zero_tensor)
print(one_tensor)
print(one_tensor.dtype) # by default, all tensors use float32 (single-point precision) initially
# Multiplication symbol * leads to Hadamard product
print(random_tensor)
print(one_tensor * random_tensor)
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
torch.float32
tensor([[0.0879, 0.6826, 0.4789, 0.1849],
[0.7974, 0.9331, 0.8372, 0.3934],
[0.4137, 0.7374, 0.8922, 0.0088]])
tensor([[0.0879, 0.6826, 0.4789, 0.1849],
[0.7974, 0.9331, 0.8372, 0.3934],
[0.4137, 0.7374, 0.8922, 0.0088]])
one_to_ten = torch.arange(start=1, end=11, step=1)
print(one_to_ten)
tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
ten_zeros = torch.zeros_like(input=one_to_ten)
print(ten_zeros)
tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
Tensor datatypes¶
Note: Tensor datatypes is one of the 3 big errors one often runs into in PyTorch:
- Tensors not the right datatype
- Tensors not the right shape
- Tensors not on the right device
# Float 32 tensor
float_32_tensor = torch.tensor([3.0, 6.0, 9.0],
dtype=torch.float32,
device=None,
requires_grad=False)
print(float_32_tensor)
print(float_32_tensor.dtype)
tensor([3., 6., 9.]) torch.float32
float_16_tensor = float_32_tensor.type(torch.float16)
print(float_16_tensor)
print(float_16_tensor.dtype)
tensor([3., 6., 9.], dtype=torch.float16) torch.float16
float_16_tensor * float_32_tensor #
tensor([ 9., 36., 81.])
some_tensor = torch.rand(3, 4)
print(some_tensor)
print(f"Datatype of tensor: {some_tensor.dtype}")
print(f"Shape of tensor: {some_tensor.shape}")
print(f"Device that tensor is on: {some_tensor.device}")
tensor([[0.2600, 0.3511, 0.7676, 0.6426],
[0.9504, 0.4816, 0.0339, 0.0265],
[0.9296, 0.9317, 0.4725, 0.8148]])
Datatype of tensor: torch.float32
Shape of tensor: torch.Size([3, 4])
Device that tensor is on: cpu
Manipulating Tensors (Tensor Operation)¶
- Addition
- Subtraction
- Hadamard multiplication
- Matrix Multiplication
- Division? (Inversion?)
tensor = torch.tensor([1, 2, 3])
print(tensor + 10)
print(tensor * 10)
print(tensor - 10)
print(torch.add(tensor, 10))
tensor([11, 12, 13]) tensor([10, 20, 30]) tensor([-9, -8, -7]) tensor([11, 12, 13])
tensor1 = torch.tensor([[1, 2],
[3, 4]])
tensor2 = torch.tensor([[4, 5],
[6, 7]])
print(tensor1 @ tensor2)
print(torch.matmul(tensor1, tensor2))
print(torch.mm(tensor1, tensor2))
%timeit tensor1 @ tensor2
tensor([[16, 19],
[36, 43]])
tensor([[16, 19],
[36, 43]])
tensor([[16, 19],
[36, 43]])
1.88 μs ± 96.6 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
%%time
# Hard coding matrix multiplication
C = torch.tensor([[0, 0], [0, 0]])
for i in range(2):
for j in range(2):
for k in range(2):
C[i, j] += tensor1[i, k] * tensor2[k, j]
print(C)
tensor([[16, 19],
[36, 43]])
CPU times: user 1.94 ms, sys: 394 μs, total: 2.34 ms
Wall time: 1.92 ms
Tensor Aggregation
x = torch.arange(1, 100, 10)
print(x)
print(x.dtype)
print(torch.min(x), x.min())
print(torch.max(x), x.max())
print(torch.mean(x.type(torch.float32)), x.type(torch.float32).mean())
print(torch.sum(x), x.sum())
print(torch.argmin(x), x.argmin())
print(torch.argmax(x), x.argmax())
print(x[9])
tensor([ 1, 11, 21, 31, 41, 51, 61, 71, 81, 91]) torch.int64 tensor(1) tensor(1) tensor(91) tensor(91) tensor(46.) tensor(46.) tensor(460) tensor(460) tensor(0) tensor(0) tensor(9) tensor(9) tensor(91)
# Reshaping, stacking, squeezing, unsqueezing PyTorch tensors
import torch
x = torch.arange(1, 10)
x, x.shape
(tensor([1, 2, 3, 4, 5, 6, 7, 8, 9]), torch.Size([9]))
x_reshaped = x.reshape(3, 3)
x_reshaped, x_reshaped.shape
(tensor([[5, 2, 3],
[4, 5, 6],
[7, 8, 9]]),
torch.Size([3, 3]))
z = x.view(1, 9)
z, z.shape
z[:, 0] = 5
z, x # changes in z will affect x, stored in same memory location
(tensor([[5, 2, 3, 4, 5, 6, 7, 8, 9]]), tensor([5, 2, 3, 4, 5, 6, 7, 8, 9]))
x_stacked = torch.stack([x, x, x, x], dim=1)
x_h_stacked = torch.hstack([x, x, x, x])
x_v_stacked = torch.vstack([x, x, x, x])
print(x_stacked)
print(x_h_stacked)
print(x_v_stacked)
tensor([[5, 5, 5, 5],
[2, 2, 2, 2],
[3, 3, 3, 3],
[4, 4, 4, 4],
[5, 5, 5, 5],
[6, 6, 6, 6],
[7, 7, 7, 7],
[8, 8, 8, 8],
[9, 9, 9, 9]])
tensor([5, 2, 3, 4, 5, 6, 7, 8, 9, 5, 2, 3, 4, 5, 6, 7, 8, 9, 5, 2, 3, 4, 5, 6,
7, 8, 9, 5, 2, 3, 4, 5, 6, 7, 8, 9])
tensor([[5, 2, 3, 4, 5, 6, 7, 8, 9],
[5, 2, 3, 4, 5, 6, 7, 8, 9],
[5, 2, 3, 4, 5, 6, 7, 8, 9],
[5, 2, 3, 4, 5, 6, 7, 8, 9]])
tensor([5, 2, 3, 4, 5, 6, 7, 8, 9])
y = torch.zeros(1, 2, 3, 2, 3)
print(y)
print(y.squeeze(), y.squeeze().shape)
tensor([[[[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]],
[[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]]]])
tensor([[[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]],
[[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]]]) torch.Size([2, 3, 2, 3])
print(x)
print(x.unsqueeze(dim=0))
print(x.unsqueeze(dim=1))
tensor([5, 2, 3, 4, 5, 6, 7, 8, 9])
tensor([[5, 2, 3, 4, 5, 6, 7, 8, 9]])
tensor([[5],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9]])
random_image = torch.rand(size=(200, 400, 3))
plt.imshow(random_image)
print(f"Shape of random_image: {random_image.shape}")
random_image_permuted = random_image.permute(2, 1, 0)
print(f"Shape of random_image_permuted: {random_image_permuted.shape}")
#random_image_permuted =
Shape of random_image: torch.Size([200, 400, 3]) Shape of random_image_permuted: torch.Size([3, 400, 200])

# Indexing from PyTorch tensors is similar to indexing from NumPy arrays
x = torch.arange(1, 10).reshape(1, 3, 3)
print(x, x.shape)
print(x[0])
print(x[0][0])
print(x[0][0][0])
print(x[0][:, 2])
tensor([[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]]) torch.Size([1, 3, 3])
tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
tensor([1, 2, 3])
tensor(1)
tensor([3, 6, 9])
# PyTorch tensors & NumPy
np_array = np.arange(1.0, 8.0)
pytorch_tensor = torch.from_numpy(np_array) # since default NumPy dtype is FP64, PyTorch will reflect this in torch.from_numpy()
print(np_array)
print(pytorch_tensor)
T = torch.ones(7)
numpy_arr = T.numpy()
print(T)
print(numpy_arr)
print(numpy_arr.dtype) #now default is FP32 b/c torch tensors default to FP32
[1. 2. 3. 4. 5. 6. 7.] tensor([1., 2., 3., 4., 5., 6., 7.], dtype=torch.float64) tensor([1., 1., 1., 1., 1., 1., 1.]) [1. 1. 1. 1. 1. 1. 1.] float32
random_tensor_A = torch.rand(3, 4)
random_tensor_B = torch.rand(3, 4)
print(random_tensor_A)
print(random_tensor_B)
print(random_tensor_A == random_tensor_B)
tensor([[0.6327, 0.6428, 0.5100, 0.1919],
[0.9144, 0.7456, 0.6312, 0.8555],
[0.9164, 0.6492, 0.5402, 0.2073]])
tensor([[0.0675, 0.4836, 0.7717, 0.0868],
[0.9814, 0.8618, 0.9880, 0.1541],
[0.8092, 0.0201, 0.0600, 0.7161]])
tensor([[False, False, False, False],
[False, False, False, False],
[False, False, False, False]])
# Set a random seed
seed = 42
torch.manual_seed(seed)
random_tensor_C = torch.rand(3, 4)
random_tensor_D = torch.rand(3, 4)
print(random_tensor_C)
print(random_tensor_D)
tensor([[0.8823, 0.9150, 0.3829, 0.9593],
[0.3904, 0.6009, 0.2566, 0.7936],
[0.9408, 0.1332, 0.9346, 0.5936]])
tensor([[0.8694, 0.5677, 0.7411, 0.4294],
[0.8854, 0.5739, 0.2666, 0.6274],
[0.2696, 0.4414, 0.2969, 0.8317]])
# Running tensors and PyTorch objects on GPUs (and making faster computations)
!nvidia-smi
Sat Jan 24 20:22:27 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.188 Driver Version: 573.71 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4050 ... On | 00000000:01:00.0 Off | N/A |
| N/A 25C P3 14W / 39W | 0MiB / 6141MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
# Check for GPU access with PyTorch
torch.cuda.is_available()
# If want code to be device-agnostic, then can check if GPU exists:
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
# Count number of GPUs
print(torch.cuda.device_count())
cuda 1
# Putting tensors & models on GPU
my_tensor = torch.tensor([1, 2, 3])
print(my_tensor, my_tensor.device) #default to CPU
# To move tensor to GPU (if GPU available as encoded in device variable above)
my_tensor_on_gpu = my_tensor.to(device)
print(my_tensor_on_gpu)
print(my_tensor_on_gpu.device)
# Since NumPy only works on CPU, sometimes one may want to perform some arithmetic
# with NumPy arrays, in which case one would like to move a tensor back onto CPU,
# then convert to NumPy array.
my_tensor_on_cpu = my_tensor_on_gpu.to("cpu") # or can do my_tensor_on_gpu.cpu()
print(my_tensor_on_cpu)
print(my_tensor_on_cpu.device)
print(my_tensor_on_cpu.numpy())
tensor([1, 2, 3]) cpu tensor([1, 2, 3], device='cuda:0') cuda:0 tensor([1, 2, 3]) cpu [1 2 3]
Exercise Solutions:
#1 Read the documentation on torch.tensor and torch.Cuda
#2
random_tensor = torch.rand(size=(7, 7))
print(random_tensor)
#3
another_random_tensor = torch.rand(size=(1, 7))
print(random_tensor@another_random_tensor.T)
tensor([[0.5159, 0.1636, 0.0958, 0.8985, 0.5814, 0.9148, 0.3324],
[0.6473, 0.3857, 0.4778, 0.1955, 0.6691, 0.6581, 0.4897],
[0.3875, 0.1918, 0.8458, 0.1278, 0.7048, 0.3319, 0.2588],
[0.5898, 0.2403, 0.6152, 0.5982, 0.1288, 0.5832, 0.7130],
[0.6979, 0.4371, 0.0901, 0.4229, 0.6737, 0.3176, 0.6898],
[0.8330, 0.2389, 0.5049, 0.7067, 0.5392, 0.5418, 0.5624],
[0.1069, 0.5393, 0.8462, 0.9506, 0.7939, 0.5670, 0.7335]])
tensor([[1.8984],
[1.4171],
[1.1102],
[1.5038],
[1.7249],
[1.8912],
[2.3290]])
#4
seed = 1234
torch.manual_seed(seed) #this actually seeds both CPU & GPU with same seed-->same behavior
random_tensor = torch.rand(size=(7, 7), device=device)
#random_tensor = random_tensor.to(device)
print(random_tensor)
another_random_tensor = torch.rand(size=(1, 7), device=device)
#another_random_tensor = another_random_tensor.to(device)
print(random_tensor@another_random_tensor.T)
tensor([[0.1272, 0.8167, 0.5440, 0.6601, 0.2721, 0.9737, 0.3903],
[0.3394, 0.5451, 0.7312, 0.3864, 0.5959, 0.7578, 0.2126],
[0.7198, 0.9845, 0.5518, 0.0981, 0.0582, 0.5839, 0.1083],
[0.9461, 0.3170, 0.8328, 0.6676, 0.2886, 0.9022, 0.8115],
[0.1784, 0.9534, 0.1486, 0.3882, 0.7977, 0.1752, 0.5777],
[0.1949, 0.8499, 0.3125, 0.2156, 0.0383, 0.4934, 0.3138],
[0.3121, 0.5664, 0.1266, 0.7097, 0.0040, 0.5147, 0.2811]],
device='cuda:0')
tensor([[0.9558],
[1.2227],
[0.9335],
[1.6030],
[0.9344],
[0.5282],
[0.5664]], device='cuda:0')
#4 (seeding the GPU, but then random tensors must be created there!)
seed = 1234
torch.cuda.manual_seed(seed)
random_tensor = torch.rand(size=(7, 7), device=device)
print(random_tensor)
another_random_tensor = torch.rand(size=(1, 7), device=device)
print(random_tensor@another_random_tensor.T)
tensor([[0.1272, 0.8167, 0.5440, 0.6601, 0.2721, 0.9737, 0.3903],
[0.3394, 0.5451, 0.7312, 0.3864, 0.5959, 0.7578, 0.2126],
[0.7198, 0.9845, 0.5518, 0.0981, 0.0582, 0.5839, 0.1083],
[0.9461, 0.3170, 0.8328, 0.6676, 0.2886, 0.9022, 0.8115],
[0.1784, 0.9534, 0.1486, 0.3882, 0.7977, 0.1752, 0.5777],
[0.1949, 0.8499, 0.3125, 0.2156, 0.0383, 0.4934, 0.3138],
[0.3121, 0.5664, 0.1266, 0.7097, 0.0040, 0.5147, 0.2811]],
device='cuda:0')
tensor([[0.9558],
[1.2227],
[0.9335],
[1.6030],
[0.9344],
[0.5282],
[0.5664]], device='cuda:0')
#6 (just to prove that torch.manual_seed() seeds both CPU and GPU devices)
torch.manual_seed(1234)
T1_rand = torch.rand(size=(2, 3), device="cuda")
T2_rand = torch.rand(size=(2, 3), device="cuda")
print(T1_rand)
print(T2_rand)
#7
T = T1_rand.T@T2_rand
print(T)
#8
print(torch.max(T), T.max())
print(torch.min(T), T.min())
#9
print(torch.argmax(T), T.argmax())
print(torch.argmin(T), T.argmin())
#10
T_rand = torch.rand(size=(1, 1, 1, 10))
print(T_rand, T_rand.shape)
T_rand = T_rand.squeeze()
print(T_rand, T_rand.shape)
tensor([[0.1272, 0.8167, 0.5440],
[0.6601, 0.2721, 0.9737]], device='cuda:0')
tensor([[0.6208, 0.0276, 0.3255],
[0.1114, 0.6812, 0.3608]], device='cuda:0')
tensor([[0.1525, 0.4531, 0.2796],
[0.5374, 0.2079, 0.3640],
[0.4462, 0.6783, 0.5284]], device='cuda:0')
tensor(0.6783, device='cuda:0') tensor(0.6783, device='cuda:0')
tensor(0.1525, device='cuda:0') tensor(0.1525, device='cuda:0')
tensor(7, device='cuda:0') tensor(7, device='cuda:0')
tensor(0, device='cuda:0') tensor(0, device='cuda:0')
tensor([[[[0.0290, 0.4019, 0.2598, 0.3666, 0.0583, 0.7006, 0.0518, 0.4681,
0.6738, 0.3315]]]]) torch.Size([1, 1, 1, 10])
tensor([0.0290, 0.4019, 0.2598, 0.3666, 0.0583, 0.7006, 0.0518, 0.4681, 0.6738,
0.3315]) torch.Size([10])