
Problem: Why is it important to learn how to learn?
Solution: In a post-AGI world where each day feels like swallowing a fire hose of new (mis!)information (especially as a researcher), the most important arrow one can have in the quiver is the ability to learn deeply, rapidly and with long shelf life. Equivalently, each piece of knowledge is a vector \(\mathbf k:=(\mu,\nu,\rho)\in (0,\infty)^3\) along \(3\) orthogonal axes (understanding, velocity, and retention), and the goal is for all \(\mathbf k\)-vectors to flow along the vector field of enlightenment:
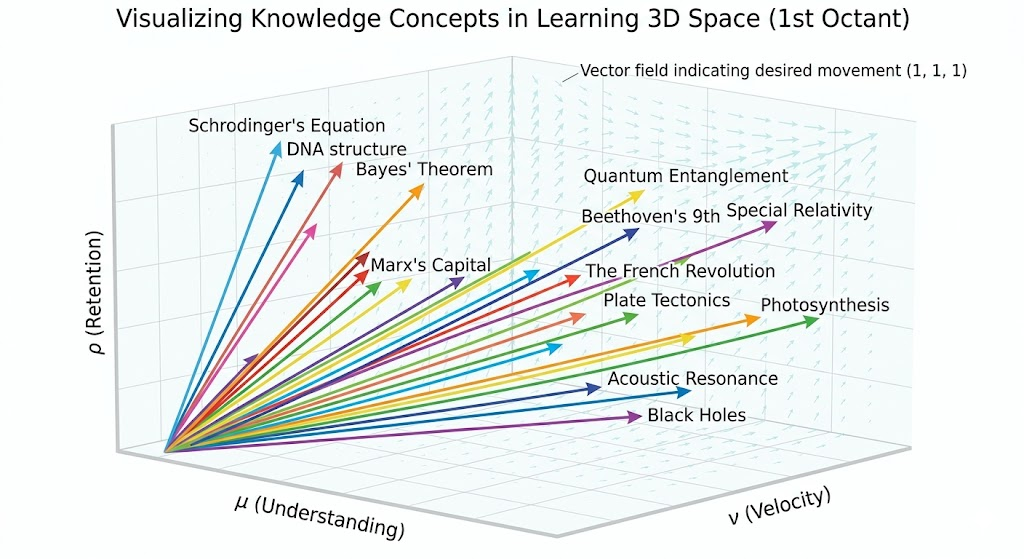
Equivalently, in the time domain, it is essential to recognize that learning is just fighting an uphill battle against the entropy of the Ebbinghaus \(\mu(t)\) forgetting curve:
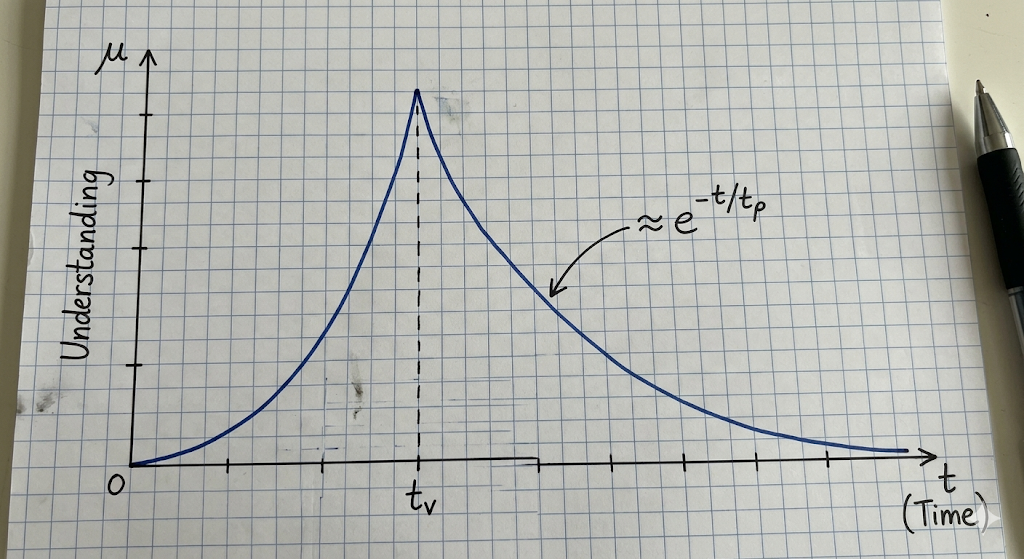
(possible ODE \(\dot{\mu}=-\mu/t_{\rho}+\mu(1-\mu/\mu^*)/t_v\)?)
Problem: Describe a general (i.e. field-independent) method for learning any topic in any field deeply.
Solution: The ACADEMIA learning method involves a sequence of \(8\) nonlinear steps (i.e. one will often bounce back and forth among them). For each step, one should only invoke LLM assistance after a sincere personal endeavour has been made.
- Ask: questions to anchor one’s razor focus on as one seeks the answers through learning.
- Consolidate: compress/condense/compact raw material as rigorous, concise bullets, exploiting field-specific tricks.
- Analogies: connect/bridge/one-to-one dictionary mappings onto one’s prior knowledge graph as much as possible.
- Diagrams: graphs (both \(\{(x,f(x))\}\) and \((V,E)\)), matrices/tables, geometric constructions, heuristic representations, etc.
- Examples: concrete numbers to clarify abstract scaffolding.
- Mentor: Feynman technique of explaining without jargon as if to a \(12\)-year old.
- Interrogate: play devil’s advocate, adversarially seek to find flaws or inefficiencies in assumptions and conventional wisdom.
- Acronym: summarize the new understanding gained with a memorable mnemonic.
Problem: Demonstrate a walk-through of the ACADEMIA learning method applied to the financial topic of stocks and bonds.
Solution:
- A:
Problem: While the above demonstrates how to learn deeply (i.e. along the \(\mu\)-axis), it does not fully address the issues of how to learn quickly \(\nu\) or how to ensure retention \(\rho\).
Solution:
- Forcing function: being in the right external environment with pressure and impetus to keep one motivated to learn (e.g. a library/office/coffee shop with the right incentive structures/deadlines).
- Preparation: get into the right frame of mind by taking deep breaths until one feels sufficiently calm and steady to begin a deeply focused session of learning. Earmuffs on.
- Reinforce: solve or answer (possibly LLM-generated) problems/exercises/quizzes/hands-on interactives/coding programs with (possibly LLM-generated) solutions.
Problem: How about high velocity? And high retention?
Solution: Listening to podcasts, popular talks, YouTube videos, etc. while instructive in their own right are not a substitute for doing it oneself.
Problem: What is the attitude with which one should approach learning?
Solution: One should only ever compare oneself to who they were yesterday, and ask whether or not one has improved from then. With consistent routines, growth compounds exponentially; \(1.01^{365}\approx 38\). Finally, practice what you preach! Also, learn for the joy of learning is best, though not always possible. The systematic method described above can seem a bit intimidating, but the little bit of extra time spent is hopefully well worth it in the long run, and overtime we will get better/faster at it (autopilot) and also improve upon it through feedback loops.
(also, the problem of how to structure one’s breaks? Pomodoro seems a bit too rigid, can interrupt flow state/groove. )
(also, comments on how to get into the groove state in the first place, I think getting over that initial activation energy barrier is key)
(another comment: perhaps meditation before working? or some form of deep breaths/emotional control to get primed for the right state of mind?)
(keeping feet stationary on the floor, no shaking, perhaps can build some kind of mechanical lock-in for our feet? And also about standing desks…)
(also, about making tasks as modular as possible, ideally can be completed in <30 minutes? So before starting a session of work, write up the to-do list to sharpen scope and prevent distractions)
(allowing downtime for the mind to wander/think about something from earlier but deliberately try to find a crack/new perspective? Point is research is by definition trying to discover out-of-distribution stuff, so need to do this exercise. Actually, how about we just play the connection game, us adversarial vs. Gemini, and also Gemini adversarial vs. us, flesh out as many connections as you can think of in that time, and write up any interesting ones somewhere for later thought? You should just vibe code this. Also comment on the Poincare theory of 4 hours/day?)
Problem: Describe some physics-specific learning tricks.
Solution: (to do: acronym for all of this as one should practice what one preaches!)
personal cognitively consonant notation
- Technique #\(1\): resist simplification temptation, group variables into dimensionally meaningful groups each with a clear interpretation, e.g. density of states in \(k\)-space for a free \(3\)D electron gas is \(g(k)=2\times V/(2\pi)^3\times 4\pi k^2=Vk^2/\pi^2\), impedance of a non-dispersive string is \(Z=T/\sqrt{T/\mu}=\sqrt{T\mu}\), energy levels of a particle in a box \(E_n=\hbar^2(n\pi/L)^2/2m=n^2\pi^2\hbar^2/2mL^2\), etc.
- Technique #\(2\): dimensional analysis, find how quantities scale without regards to numerical pre-factors, e.g. from Navier-Stokes equations, inertial forces (e.g. air resistance) scale like \(F_{\rho}/a^3\sim\rho v^2/a\Rightarrow F_{\rho}\sim \rho a^2v^2\) whereas viscous forces (e.g. Stokes drag) scale like \( F_{\eta}/a^3\sim\eta v/a^2\Rightarrow F_{\eta}\sim\eta av\), so the Reynolds numbers is \(\text{Re}:=F_{\rho}/F_{\eta}\sim\rho av/\eta\).
- Technique #\(3\): black box thinking, view complex systems solely in terms of inputs and outputs, e.g. Fabry-Perot interferometers as tunable diffraction gratings, transformers as sequence-to-sequence models, operational amplifiers, etc.
- Technique #\(4\): exploit isomorphisms, understand a less intuitive concept \(X\) using the existence of an isomorphism \(X\cong Y\) with a more intuitive concept \(Y\), e.g. driven \(RLC\) circuits as damped, driven harmonic oscillators.
- Technique #\(5\): toy models, approximate complex systems by their simplest non-trivial irreducibles, e.g. a ferromagnet as an Ising/Heisenberg lattice, etc.
- Technique #\(6\): remember numerical values, one can sanity-check and remember formulas simply from the order of magnitudes of the quantities (this can be aided by software such as Anki), e.g. since \(N_A\sim 10^{23}\) and \(k_B\sim 10^{-23}\) (both in SI units), one expects \(N_Ak_B\sim O(1)\). But \(R\approx 8.3\sim O(1)\), hence \(N_Ak_B=R\).
- Technique #\(7\): systematize, find general recipes/frameworks for approaching problems in a field, e.g. in quantum mechanics, once one has a clear idea of \((\mathcal H,H)\), the rest is just diagonalization, in ML one has the PRAC-DTDT-ID algorithm, etc.
- Technique #\(8\): draw diagrams, annotate and label the diagram as a concept graph, e.g. the unit circle complex phase plane diagram for the \(1\)D harmonic oscillator creation/annihilation operators (this one also nicely combines Technique #\(2\)).
- Technique #\(9\): acronyms/checklists, e.g. PRAC-DTDT-ID
- Technique #\(10\): teach it, blog or present to someone else.
- Technique #\(11\): latch onto key ideas, anchor everything else to it as a kind of knowledge graph extension/branch-off point, e.g. linear transformations.
Problem: What are the key points to keep in mind for machine learning?
Solution: (to do: acronym that’s better/simpler than PRAC-DTDT-ID)
- To check if one’s model \(\hat y_{\boldsymbol{\theta}}\) has any hope of training/learning successfully on some labelled dataset \(\mathcal D\), first choose a very small subset \(\mathcal D’\subset\mathcal D\) with \(|\mathcal D’|\ll |\mathcal D|\) and deliberately overfit \(\hat y_{\boldsymbol{\theta}}\) on \(\mathcal D’\), and run inference to check that \(\hat y_{\boldsymbol{\theta}}(\mathbf x_i)\approx y_i\) for all \((\mathbf x_i,y_i)\in\mathcal D’\).
- It is better to spend \(2\) days to carefully think through and implement an experiment with 95% probability of success than to spend \(2\) hours fumbling together an experiment with 5% probability of success.
- ACTUALLY INSPECT/LOOK AT YOUR DATA!
- Be meticulous, plot losses on all outputs.
- Run short (e.g. 10000-step) hyperparameter ablations (e.g. learning rate, weight decay, max_grad_norm, etc.) before a long training run, although tbh usually hyperparameters just need to be within 3 orders of magnitude or so of some value and should work, don’t fuss too much over them, quite robust if built well).
- Remember to save checkpoints, but also get rid of or move old checkpoints off disk and onto some filesystem (if this happens, some IDEs will prevent one from SSH onto those VMs, can get around this by SSH via terminal instead of IDE). I think it’s a good idea to include inside one’s CLAUDE.md some instruction about first checking the current disk space before committing new checkpoints, etc.
- Also, when running a new experiment/training, consider whether it’s possible to start from the checkpoint of a previous experiment.
- Nebius, RunPod, Andromeda, AWS, Azure are basically all VM/server providers, pay to rent GPUs (but also other purposes)
- Useful commands: nvidia-smi, watch -t nvidia-smi, claude –dangerously-skip-permissions, df -h, du -sh?
- WandB (Weights and Biases) is for logging data.
- Hugging Face is for storing/viewing large datasets in repos and storing model weights. Save important checkpoints to HF, otherwise just rm -rf ones you don’t need.
- Have a hypothesis about the outcome of each experiment you do, and understand why you are doing it.
- Use Claude to aid understanding, but not to replace it.
- Attention to detail is often what makes or breaks one’s model.
- Write pseudocode implementations.
- Take time to carefully inspect and understand one’s dataset exactly.
- Som’s \(8\) principles of deep learning:
- quantity of data
- broad data distribution
- Compute maxing
- Loss function that scales
- Don’t numerically ill-condition your model.
- Information wants to be free
- Training/inference mismatch
- Batch size