
Problem: Give a broad sketch of the current state of the field of research in graph neural networks.
Solution:
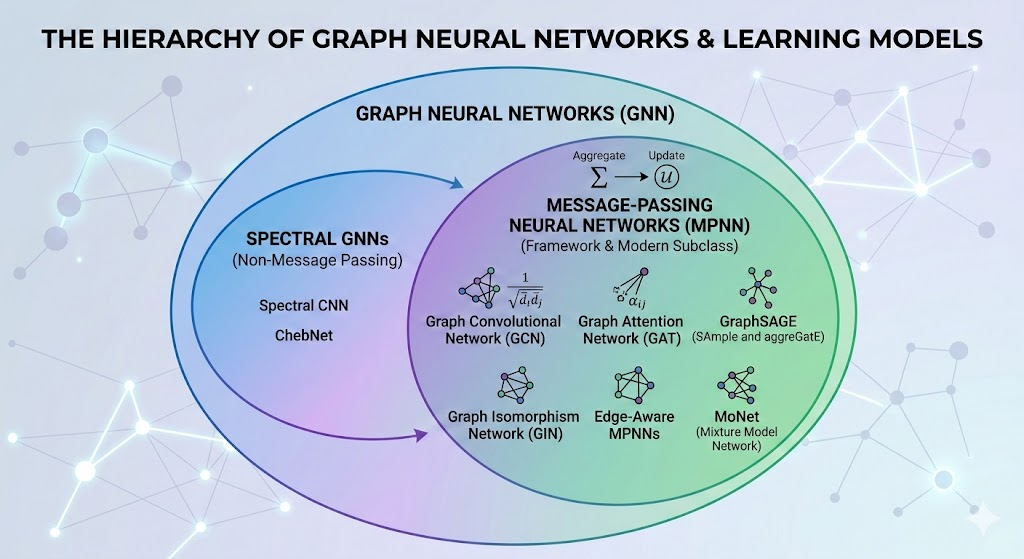
Problem: Okay, so now explain what a graph neural network (GNN) actually is.
Solution: A GNN is basically any neural network whose input is any (undirected/directed/mixed/multi) graph (e.g. molecules, social networks, citation networks, etc.). In order to be sensible, the GNN output (whatever it is, e.g. a binary classifier for molecule toxicity) has to genuinely be an intrinsic function of the graph structure alone, and in particular not depend on any arbitrary choice of “ordering” with which one might index the graph vertices and edges (i.e. the output must be either permutation equivariant or permutation invariant depending on its nature, cf. tensors vs. tensor components in some basis).
Problem: Explain the subclass of GNNs known as message-passing neural networks (MPNNs).
Solution: An MPNN, being a certain category of GNNs, starts its life by taking as input some graph \((V,E)\). More precisely, this looks like some feature vector \(\mathbf x_v\) (e.g. mass, charge, atomic number for atoms) for each vertex \(v\in V\) and possibly also a feature vector \(\mathbf x_e\) (e.g. bond length, bond energy, etc.) for each edge \(e\in E\). The idea is that, in a manner similar to a head of self-attention, each vertex \(v\in V\) wants to update its current state \(\mathbf x_v\) into some new state \(\mathbf x’_v\) by soaking in context from its neighbours, and in an analogous manner each edge \(e\in E\) also wants to update its current state \(\mathbf x_e\mapsto\mathbf x’_e\) based on its “neighbours” (thus it’s not quite the same as self-attention in which a token doesn’t just look at its nearest neighbour tokens, but at all the tokens in the context). In the general MPNN framework, this can be roughly broken down into \(3\) conceptual steps:
- Message phase: from a sender perspective, each vertex \(v\in V\) “broadcasts” a “personalized” message vector \(\mathbf m_{vv’}\) along the edge \((v,v’)\in E\) connecting it to a neighbouring vertex \(v’\in V\). This message vector \(\mathbf m_{vv’}\) is any (learnable) function of its current state \(\mathbf x_v\), the current state of the receiving neighbour vertex \(\mathbf x_{v’}\), and the current edge feature vector \(\mathbf x_{vv’}\) connecting them.
- Aggregation phase: simultaneously, from a receiver perspective, each vertex \(v\in V\) receives the broadcasted signals from its neighbouring vertices. From this perspective, it then takes all the received message vectors and synthesizes them into a single “message summary” vector \(\mathbf m_v\) which in practice is any permutation invariant function of the message vectors \(\mathbf m_{vv’}\) it received from neighbouring vertices \(v’\in V\) (e.g. their average).
- Update phase: Finally, the vertex \(v\in V\) updates its own current state \(\mathbf x_v\) to some new state \(\mathbf x’_v\) using another (learnable) function of its current state \(\mathbf x_v\) and the message summary \(\mathbf m_v\).
This \(3\)-step process represents a single forward pass through \(1\) message-passing layer; several composed together define an MPNN.
Problem: Now that the general framework of MPNN architectures has been defined, walk through the following specific examples of MPNN architectures:
- Graph convolutional networks (GCNs)
- Graph attention networks (GATs)
Solution: